Overview
Apache Gluten is a middle layer responsible for offloading JVM-based SQL engines’ execution to native engines.
1 Introduction
1.1 Problem Statement
Apache Spark is a stable, mature project that has been developed for many years. It is one of the best frameworks to scale out for processing petabyte-scale datasets. However, the Spark community has had to address performance challenges that require various optimizations over time. As a key optimization in Spark 2.0, Whole Stage Code Generation is introduced to replace Volcano Model, which achieves 2x speedup. Henceforth, most optimizations are at query plan level. Single operator’s performance almost stops growing.

On the other side, SQL engines have been researched for many years. There are a few libraries like Clickhouse, Arrow and Velox, etc. By using features like native implementation, columnar data format and vectorized data processing, these libraries can outperform Spark’s JVM based SQL engine. However, these libraries only support single node execution.
1.2 Gluten’s Solution
“Gluten” is Latin for glue. The main goal of Gluten project is to “glue” native libraries with SparkSQL. Thus, we can benefit from high scalability of Spark SQL framework and high performance of native libraries.
The basic rule of Gluten’s design is that we would reuse spark’s whole control flow and as many JVM code as possible but offload the compute-intensive data processing part to native code. Here is what Gluten does:
- Transform Spark’s whole stage physical plan to Substrait plan and send to native
- Offload performance-critical data processing to native library
- Define clear JNI interfaces for native libraries
- Switch available native backends easily
- Reuse Spark’s distributed control flow
- Manage data sharing between JVM and native
- Extensible to support more native accelerators
1.3 Target User
Gluten’s target user is anyone who wants to accelerate SparkSQL fundamentally. As a plugin to Spark, Gluten doesn’t require any change for dataframe API or SQL query, but only requires user to make correct configuration. See Gluten configuration properties here.
1.4 References
You can click below links for more related information.
2 Architecture
The overview chart is like below. Substrait provides a well-defined cross-language specification for data compute operations (see more details here). Spark physical plan is transformed to Substrait plan. Then Substrait plan is passed to native through JNI call. On native side, the native operator chain will be built out and offloaded to native engine. Gluten will return Columnar Batch to Spark and Spark Columnar API (since Spark-3.0) will be used at execution time. Gluten uses Apache Arrow data format as its basic data format, so the returned data to Spark JVM is ArrowColumnarBatch.

Currently, Gluten only supports Clickhouse backend & Velox backend. Velox is a C++ database acceleration library which provides reusable, extensible and high-performance data processing components. More details can be found from here. Gluten can also be extended to support more backends.
There are several key components in Gluten:
- Query Plan Conversion: converts Spark’s physical plan to Substrait plan.
- Unified Memory Management: controls native memory allocation.
- Columnar Shuffle: shuffles Gluten columnar data. The shuffle service still reuses the one in Spark core. A kind of columnar exchange operator is implemented to support Gluten columnar data format.
- Fallback Mechanism: supports falling back to Vanilla spark for unsupported operators. Gluten ColumnarToRow (C2R) and RowToColumnar (R2C) will convert Gluten columnar data and Spark’s internal row data if needed. Both C2R and R2C are implemented in native code as well
- Metrics: collected from Gluten native engine to help identify bugs, performance bottlenecks, etc. The metrics are displayed in Spark UI.
- Shim Layer: supports multiple Spark versions. We plan to only support Spark’s latest 2 or 3 releases. Currently, Spark-3.2, Spark-3.3 & Spark-3.4 (experimental) are supported.
3 How to Use
There are two methods for utilizing Gluten. The first is to use a pre-built JAR for a quick test of Gluten’s acceleration capabilities. The second is to compile the JAR yourself, ensuring it runs on your target platform and delivers the best possible performance.
3.1 Use a pre-Built Jar
One way is to use released jar. Here is a simple example. Currently, only centos7/8 and ubuntu20.04/22.04 are well supported. You can find a pre-built gluten release jar in Apache Gluten Download. Please be aware that the pre-built JAR is compiled using static linking via vcpkg, based on the Intel® Xeon® Gold 6252 processor. It should be compatible with most operating systems, including CentOS and Ubuntu, although performance is not guaranteed. For the optimal performance experience, we recommend using the 3.2 Custom Build to compile Gluten from source tailored to your specific platform.
spark-shell \
--master yarn --deploy-mode client \
--conf spark.plugins=org.apache.gluten.GlutenPlugin \
--conf spark.memory.offHeap.enabled=true \
--conf spark.memory.offHeap.size=20g \
--conf spark.shuffle.manager=org.apache.spark.shuffle.sort.ColumnarShuffleManager \
--jars gluten-velox-bundle-spark3.2_2.12-centos_7_x86_64-1.2.0.jar
3.2 Custom Build
To utilize Gluten with Spark, you can compile Gluten from the source and then configure it to enable the Gluten plugin. Below is a straightforward example. For more comprehensive instructions, please refer to the detailed guidance provided in the corresponding backend section.
export gluten_jar = /PATH/TO/GLUTEN/backends-velox/target/<gluten-jar>
spark-shell \
--master yarn --deploy-mode client \
--conf spark.plugins=org.apache.gluten.GlutenPlugin \
--conf spark.memory.offHeap.enabled=true \
--conf spark.memory.offHeap.size=20g \
--conf spark.driver.extraClassPath=${gluten_jar} \
--conf spark.executor.extraClassPath=${gluten_jar} \
--conf spark.shuffle.manager=org.apache.spark.shuffle.sort.ColumnarShuffleManager
...
3.2.1 Build and install Gluten with Velox backend
If you want to use Gluten Velox backend, see Build with Velox to build and install the necessary libraries. You can also find more information in Gluten with Velox backend and velox.
3.2.2 Build and install Gluten with ClickHouse backend
If you want to use Gluten ClickHouse backend, see Build with ClickHouse Backend. ClickHouse backend is developed by Kyligence, please visit Kyligence’s ClickHouse for more infomation.
3.2.3 Build options
See Build Parameters.
4 Join the Community
Contact Us
Gluten was initiated by Intel and Kyligence in 2022. Several companies are also actively participating in the development, such as BIGO, Meituan, Alibaba Cloud, NetEase, Baidu, Microsoft, etc. If you are interested in Gluten project, please contact and subscribe below mailing lists for further discussion.
Please see contact us for more information.
Source Code
Please see gluten source code for more information.
How to Contribute to Gluten
Please see contributing guide about how to make contributions.
Wechat Group
There is a Wechat group (in Chinese) which may be more friendly for PRC developers/users. Due to the limitation of wechat group, please mail to dev@gluten.apache.org.
Slack channel
For Velox backend, we recommend to use velox community.
5 Performance
We use TPCH-like and TPCDS-like as decison support benchmarks to evaluate Gluten’s performance. TPCH-like is a query set for modified from TPC-H benchmark and TPCDS-like is a query set for modified from TPC-DS benchmark. We use Parquet file format for Velox testing & MergeTree file format for Clickhouse testing, compared to Parquet file format as baseline. See Decision Support Benchmark.
Gluten + Velox backend Performance
The below test environment: single node with 3TB data on Intel® Xeon® Platinum 8592+; Spark-3.3.1 for both baseline and Gluten.
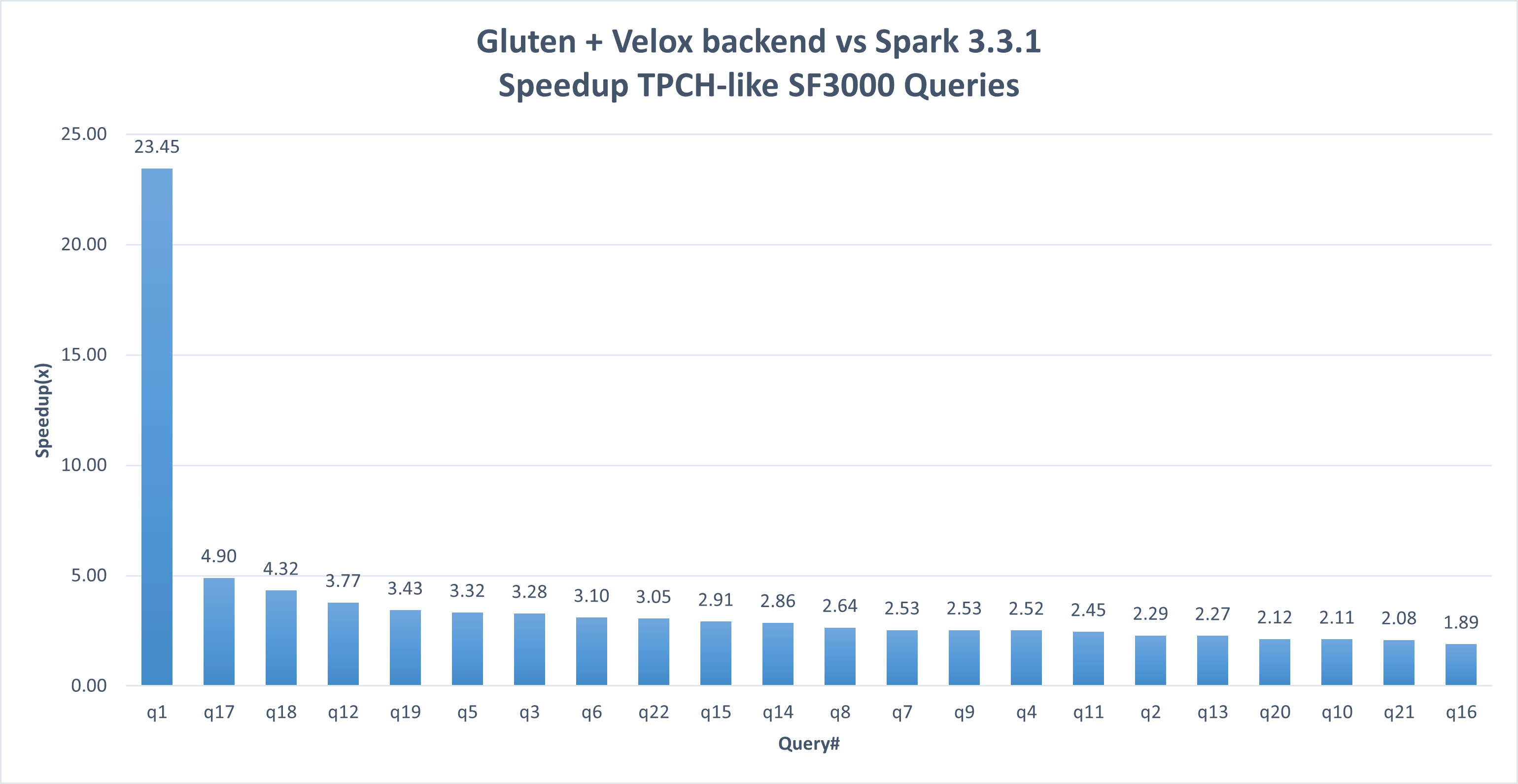
The TPCH-like result (tested in Mar. 2024) shows an overall speedup of 3.34x and up to 23.45x speedup in a single query with Gluten + Velox backend used.
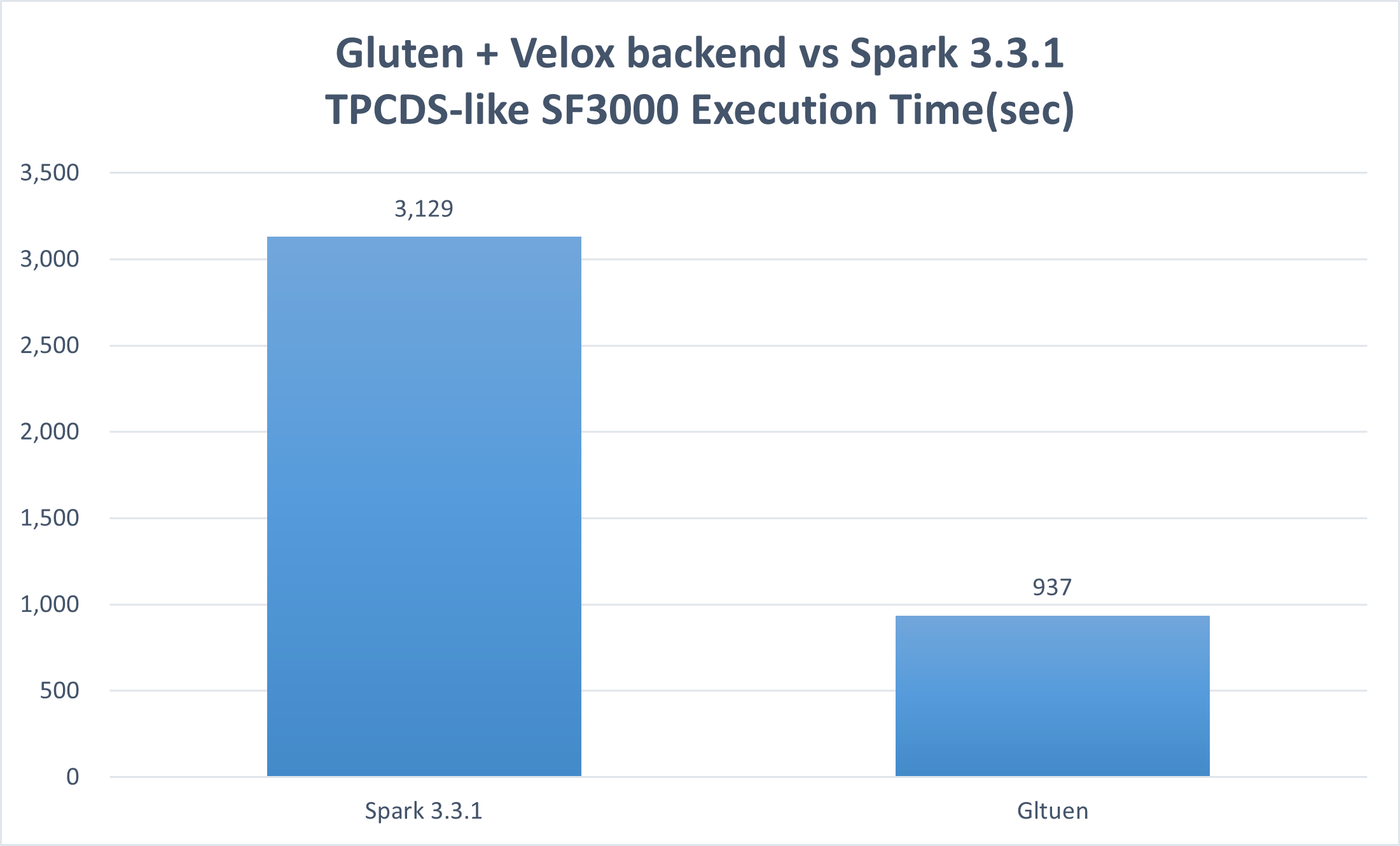
The TPCDS-like result (tested in Mar. 2024) shows an overall speedup of 3.02x and up to 13.75x speedup in a single query with Gluten + Velox backend used.
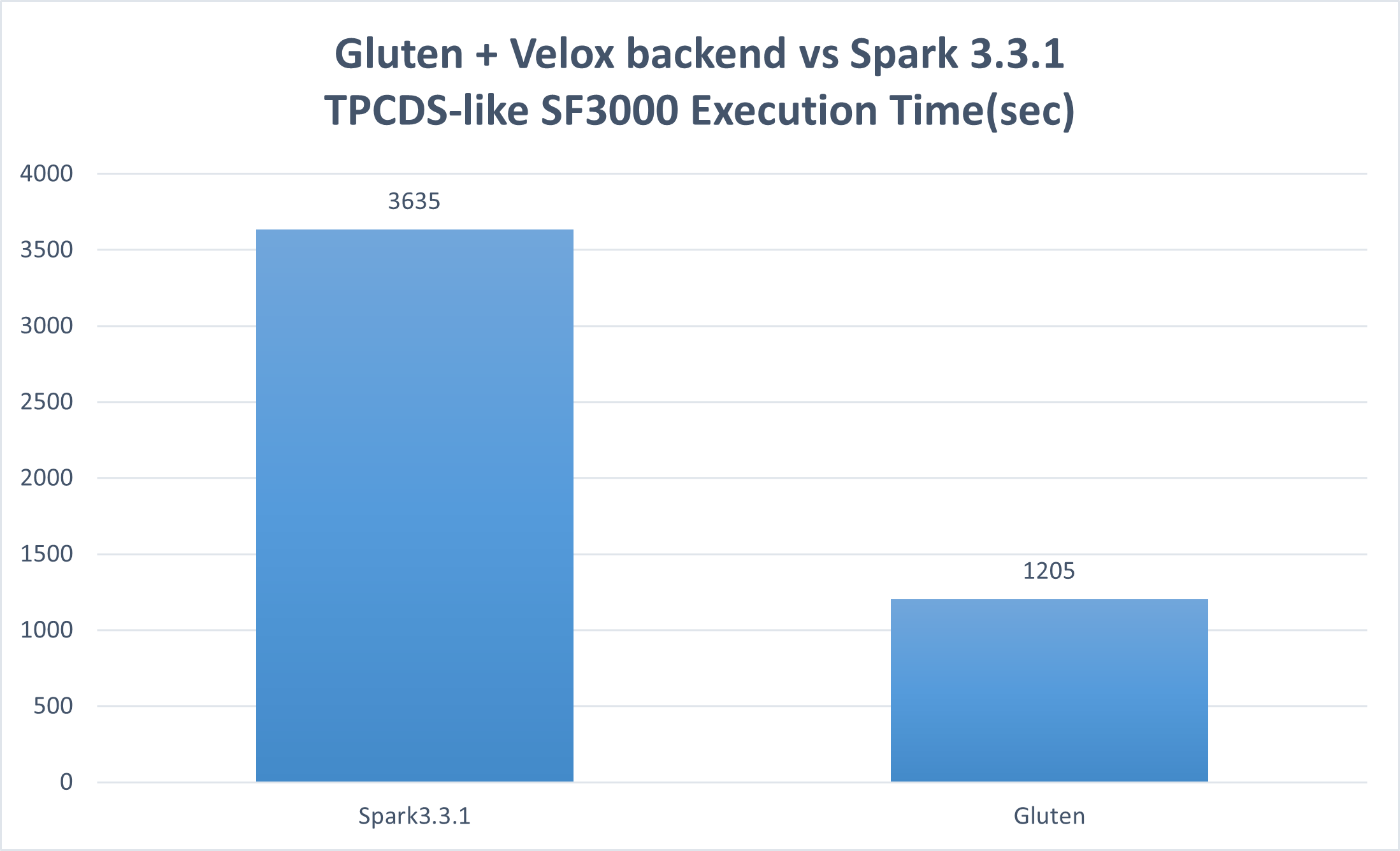
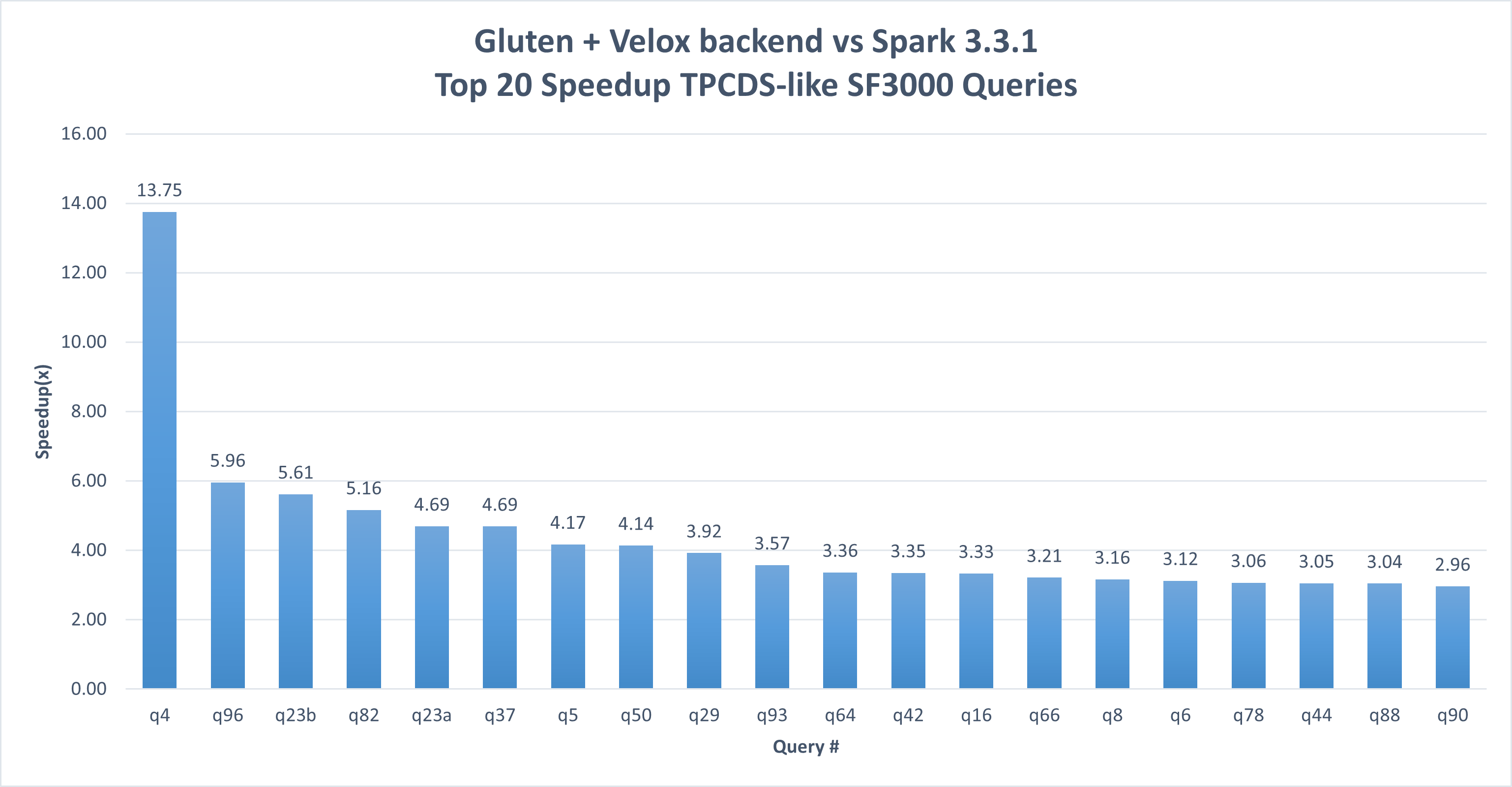
Notices & Disclaimers
Performance varies by use, configuration and other factors. Learn more on the Performance Index site. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure. Your costs and results may vary. Intel technologies may require enabled hardware, software or service activation.
Gluten + ClickHouse backend Performance
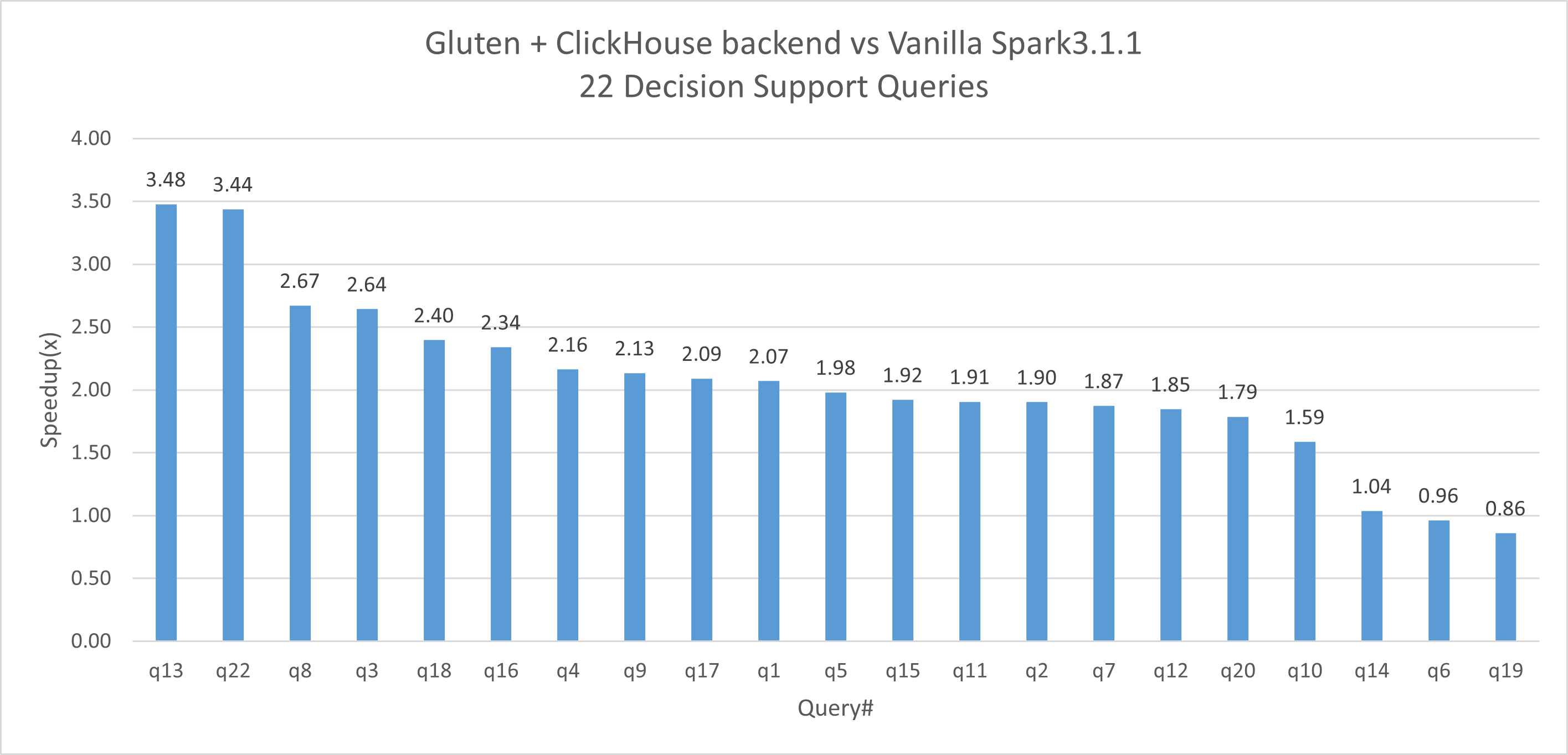
The below testing environment: a 8-nodes AWS cluster with 1TB data; Spark-3.1.1 for both baseline and Gluten. The Decision Support Benchmark1 result shows an average speedup of 2.12x and up to 3.48x speedup with Gluten Clickhouse backend.
6 Security
Gluten aims to provide secure software. If you discover a vulnerability, please report it promptly to the project’s PMC or the ASF security team. We appreciate your effort to help keep the project secure.
Thanks to our contributors
